A few years ago I started hearing about Git here and there and its various strange words like branch, index, tree, commit, clone, fork, master, origin, head, check out, check in, push and pull etc. Available tutorials were difficult to understand because they jumped straight to git commands. I approached Quora in hope for something more visual and easier to understand, then answered it myself getting most upvotes. Now posting it here on my own blog with hopefully even better explanation :)
TL;DR; Git is just a Singly Linked List where Nodes (Commits) are added on Head pointer instead of Tail. Multiple nodes can point to the same node, which creats multiple head pointers (Branches). You can create as many pointers (branches) as you like. You can even have constant pointers (Tags). Each node (commit) contains the SHA of contents of next node (previous commit) therefore if you modify contents of one node, you have to modify all nodes pointing to it. That’s all git basically is.
File OR Blob
All contents of a file are stored in a thing called blob. When a file is changed, a new blob will store complete file with all new changes. Blob is one of the basic storage units in Git. Others units/object types are Commit and Tree.
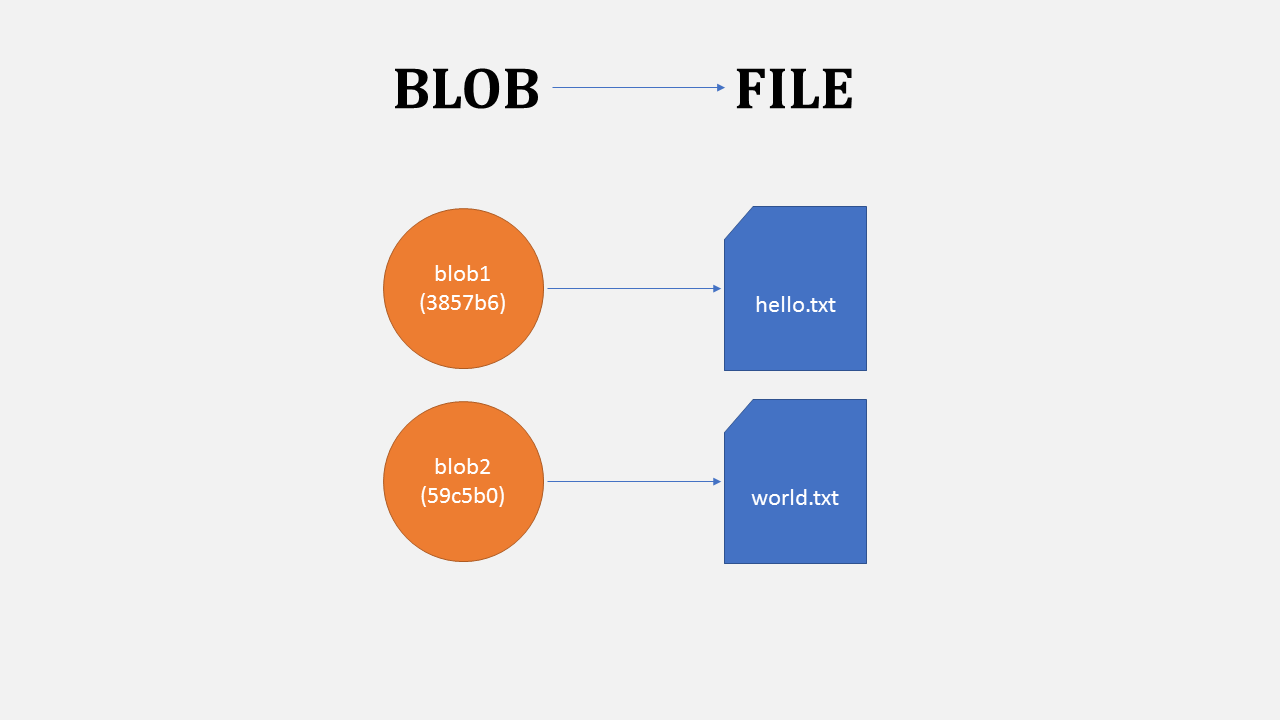
A blob stores file contents
Hash
de9f2c7fd25e1b3afad3e85a0bd17d9b100db4b3. You see a similar strange string or its short form with (first few characters) everywhere in git. This is hash (SHA1). A hash can point to a blob, a commit or a tree. It is 40 characters but only few are usually enough to identify a commit. For example GitHub shows first 10 characters.
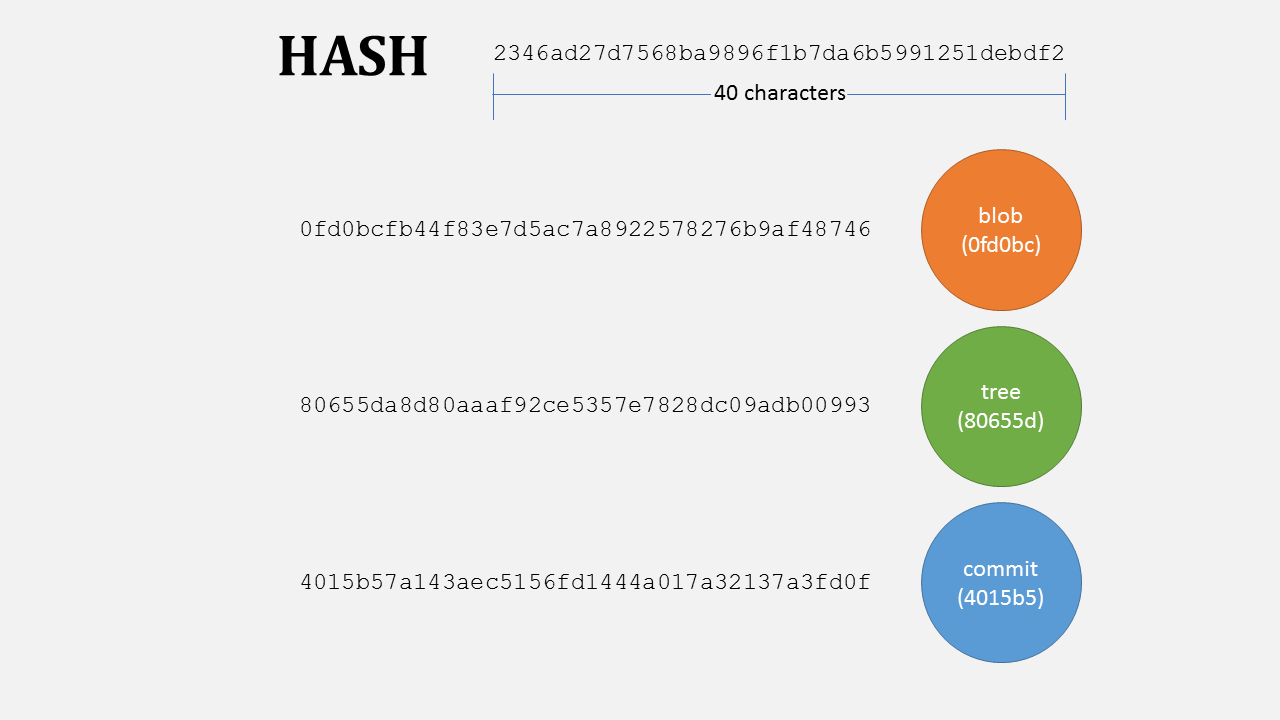
A Hash for each basic unit
Tree
Files are always stored in some directory or folder. Folders can can also contain more directories. Similarly, a tree in git represent directories for blobs and more trees.
There is always a tree on root, pointing to the tree wich contains stuff.
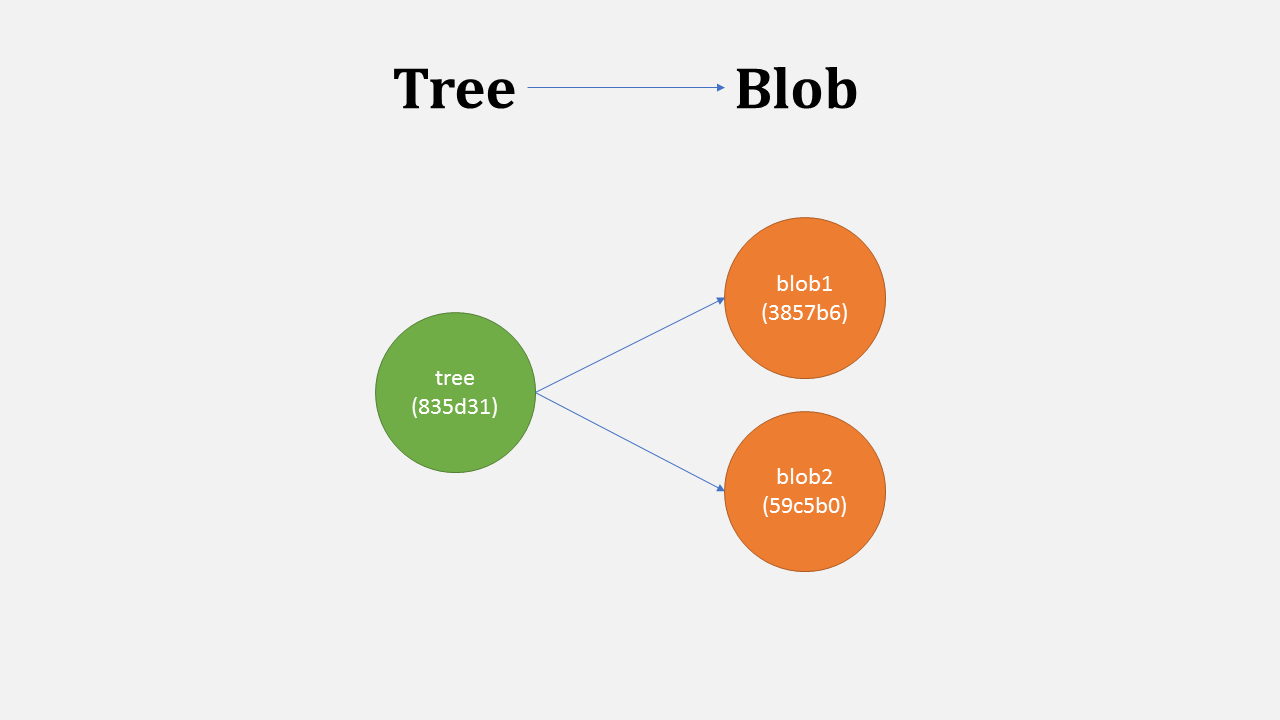
A tree stores blobs and trees
More details: Git Object: tree - GitGuys.com
Commit
Now let say you have two files. You want to save these in a way that you can get back to them in exact same state anytime later. When you save a snapshot of it with git, a commit is created pointing to the tree with two blobs (lets call them blob1 and blob2). Each commit has its own hash and it also saves your message, timestamp and your info.
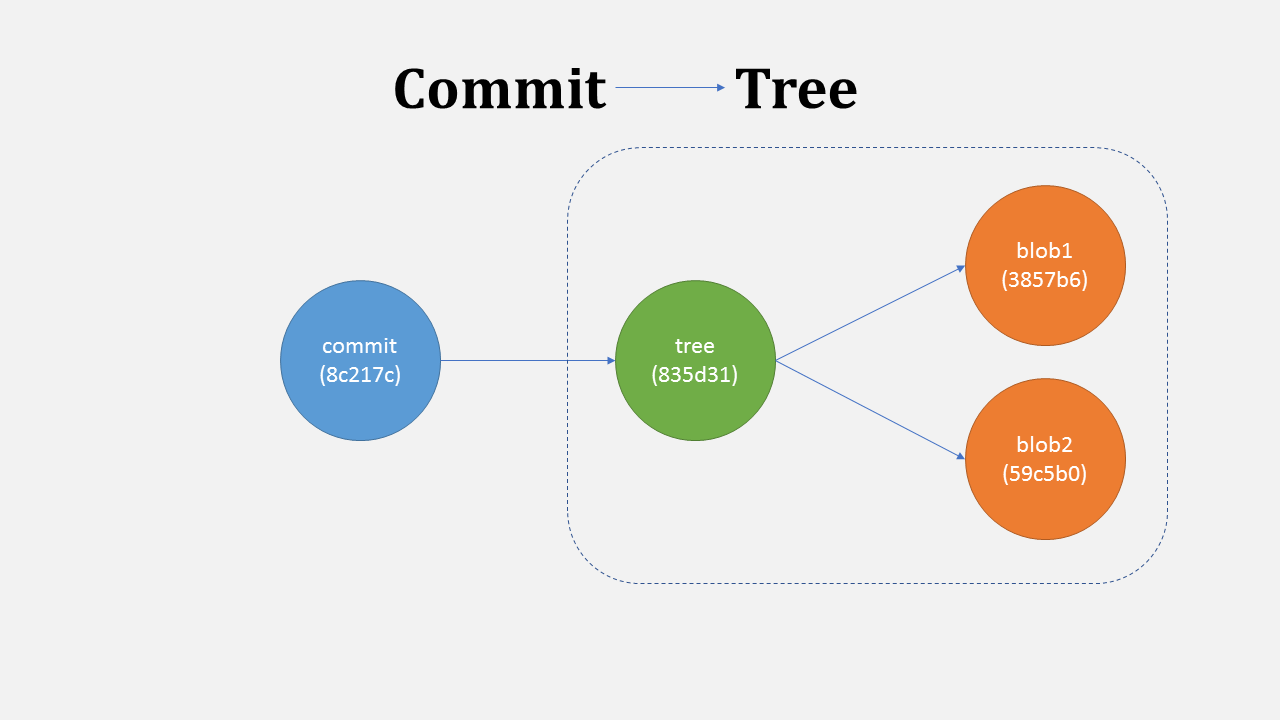
A commit points to tree
When you change one file (blob1) and commit, git will store the complete file again in a new blob (blob1c). A new tree is created with a new hash pointing to blob2 and the new blob1c. Now your git repo has both versions of a file.
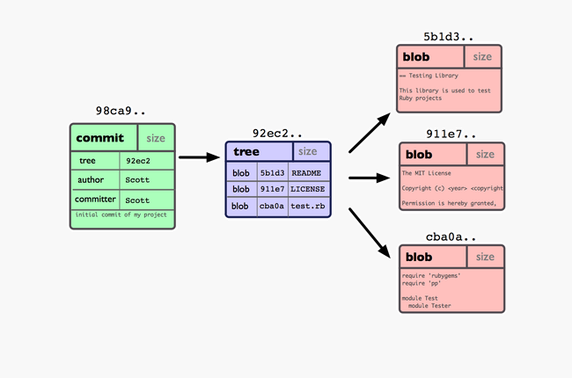
For each change there is a new blob and a new tree
Check in = Do a Commit
Check in is simply another name for doing a commit in the repository.
Check out = Load a Commit
Similary Check out is the process of loading a commit from the repository.
Working directory
This the git directory in which you are working. When you check-out a commit, your whole directory with all files is changed/replaced to match that commit (except ignored files).
Stage OR Index
The Index is your proposed next commit. Its a buffer before actual commit. It’s basically a loading dock where you get to determine what changes get shipped away. Since the working directory and what gets saved by Git are essentially decoupled, this allows the developer to build up their commits however they want. You can even stage a single individual line from your many changes and only commit that.
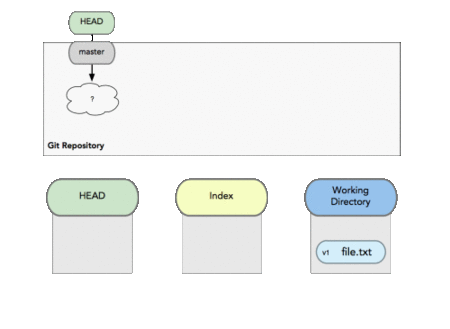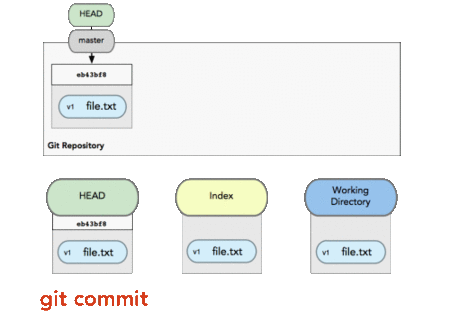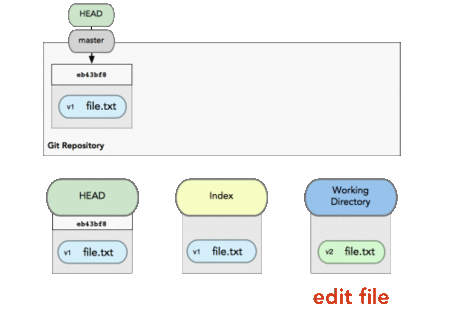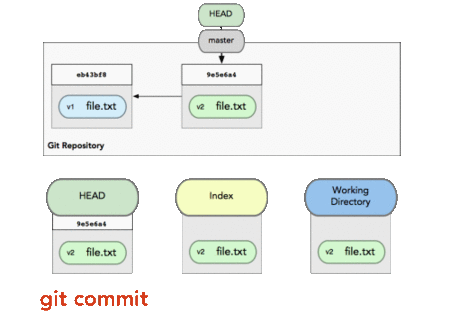
Index is the buffer before commit.
More details What is the deal with the Git Index? What is the Git Index? - GitGuys http://www.gitguys.com/topics/whats-the-deal-with-the-git-index/
More Details:
Git Object: Git Commit - GitGuys Anotomy of a Commit
History
If you make some changes and commit again, the new commit will also point to the previous commit. So each new commit only knows about its previous commit (like a ’linked list’ or ’tree’). When you keep changing files, a chain of commits maintains the history of what was done in each commit. You may load any previous commit any time.
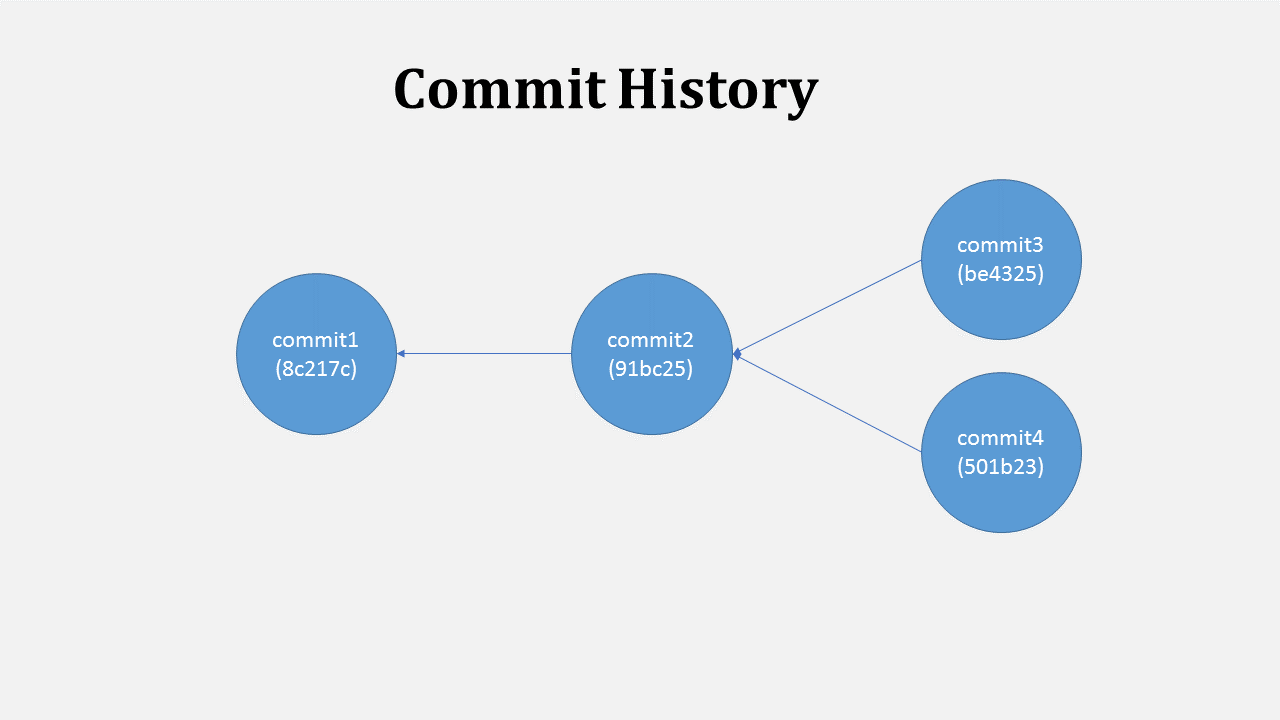
Commits are connected in chain keeping history of changes
You can see that we can have multiple commits (commit3 and commit4) pointing to same previous commit (commit2). This is called branching.
Branch
We have seen earlier that chain of commits can go in multiple directions creating multiple branches. But also note that each commit only knows about its previous commit. If you have loaded “commit4” you can go back to “commit2” but there is no way you can reach “commit3” until you have stored its address somewhere. The thing which keeps track of different branches is named simply a branch.
A branch is just a move-able pointer which keeps pointing to latest commit in that branch. Everytime you commit, it moves to that newly made commit. Git names the default branch as master.
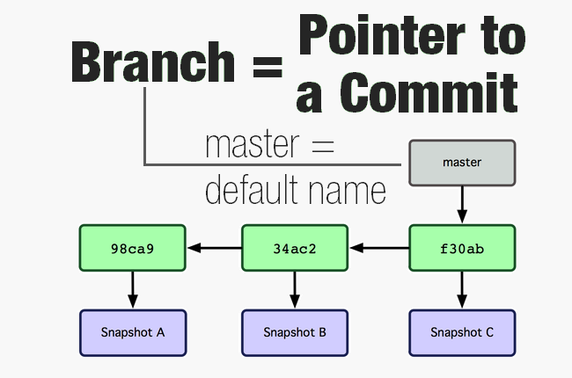
Branch is a pointer with a name, pointing to latest commit
What branch or commit which you have currently loaded is tracking by the HEAD. Head always points to the commit or branch which you are on at that time.
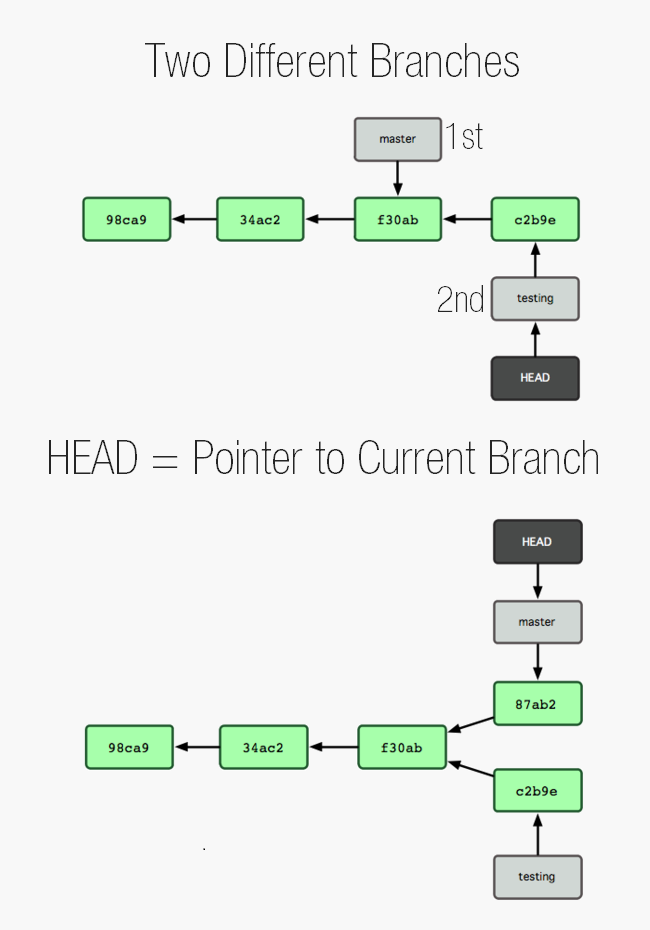
Head points to currently loaded branch
You can work on each branch independently to work on different versions of your software independently e.g. for Windows XP and Windows 7. Imagine one base Linux with all different flavors as different branches.
Visualizing branches
Many GIT Gui tools (like SmartGit) can show graph representation of branches and commits to easily see how they are connected.
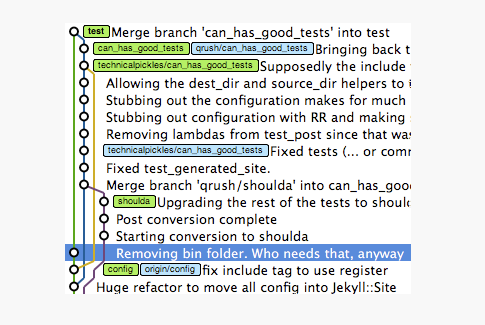
commits and branches visualized
See also:
- http://www.gitguys.com/topics/creating-and-playing-with-branches/
- http://www.gitguys.com/topics/git-show-branch-to-see-branches-and-their-commits/
- http://yyliang.cn/book/ch3-1.html
Tag (Bookmark)
Think of tag as bookmark. Where branch is a move-able pointer, a tag is immove-able pointer which always points to one specific commit. Tags are useful to specify a version. e.g. after a lots of commits and fixes you can tag a commit where everything working fine as version 1.0.
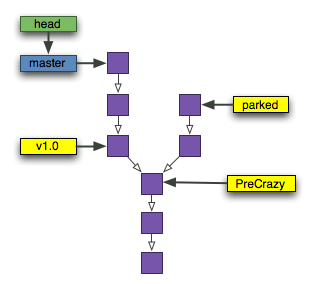
Tag is a bookmark on the specified commit
More details: Git Object: Tag | Git Tag | GitGuys.com
Rebase (Move)
Each commit, other than the first one, is depends on previous commit, we can call that one the base commit. In simplest terms, rebasing moves all commits like a building to another point or another commit.
Usually you would rebase a branch to the head of your main branch. Note that when rebasing, whole set of moved commits will be recreated so that they can fit perfectly on top of the new base.
Merge
Merge is usually an alternate of rebasing. Instead of moving that feature branch, a new “merge” commit is created which connects both branches. This new commit is made up of all changes done in both branches separately. Merge conflict can arise which must be resolved to succesfully create the merge commit.
Remote
Multiple people can work on a git repository. Each person gets his/her own copy of the whole repository. It is setup usually like this. There is one centeral repository, everyone who wants to work on it makes its clone (copy) on their own computer. For each person, the original repository from where they made the copy is a remote repo.
Clone and Fork
Clone is the process of copying a repository. After clone, the orignal repository is added as its remote. Push and Pull can be performed on that remote. Fork is just a different name used by GitHub or Bitbucket in a sense that a fork operation clones the repository to your github account instead of your computer.
Fetch
The process of getting updates/changes from remote is called fetch . When fetched, latest commits are download to the user’s computer and stored in a separate branch which tracks remote changes. These changes can be then applied with a merge command. It’s a common practice to fetch periodically to stay up to date with what everyone else is doing with the repository.
Pull
Pull downloads the changes and also applies them in one go automatically. Its basically fetch and merge in one step.
Push
Push is the process of uploading your changes to remote repository.
Sources:
- http://gitready.com/beginner/2009/02/17/how-git-stores-your-data.html
- https://jwiegley.github.io/git-from-the-bottom-up/1-Repository/3-blobs-are-stored-in-trees.html
- https://blog.thoughtram.io/git/2014/11/18/the-anatomy-of-a-git-commit.html
- https://marklodato.github.io/visual-git-guide/index-en.html
- http://gitready.com/
- http://yyliang.cn/
- http://betterexplained.com/articles/aha-moments-when-learning-git/
- http://www.gitguys.com/topics/
- http://www.ossxp.com/doc/gotgit-en/